
If AI Writes the Code, What Is Left to Learn?
If AI can produce the artifact, our courses must teach students to interrogate it

Every year, I teach a course on databases.
For weeks, I show students how to build data models and write SQL queries—carefully, step by step.
This year, during one of my lectures, a student typed a few lines of the case into Claude. Seconds later, he had a clean, well-structured data model—something I normally spend weeks teaching.
For a moment, it felt like the course had collapsed. Then came the real problem:
No one in the room could tell if the answer was right.
That’s when the question changed.
Not “How do we stop students from using AI?”
But “What are we actually trying to teach?”
I explore that question in this new piece in The Chronicle of Higher Education:
👉 https://www.chronicle.com/article/when-ai-can-do-everything-what-is-left-to-learn
In short: if AI can produce the artifact, our courses must teach students to interrogate it—frame the problem, question the output, and take responsibility for the answer.
For those of you who do not have access to The Chronicle, here is the full text of my article:
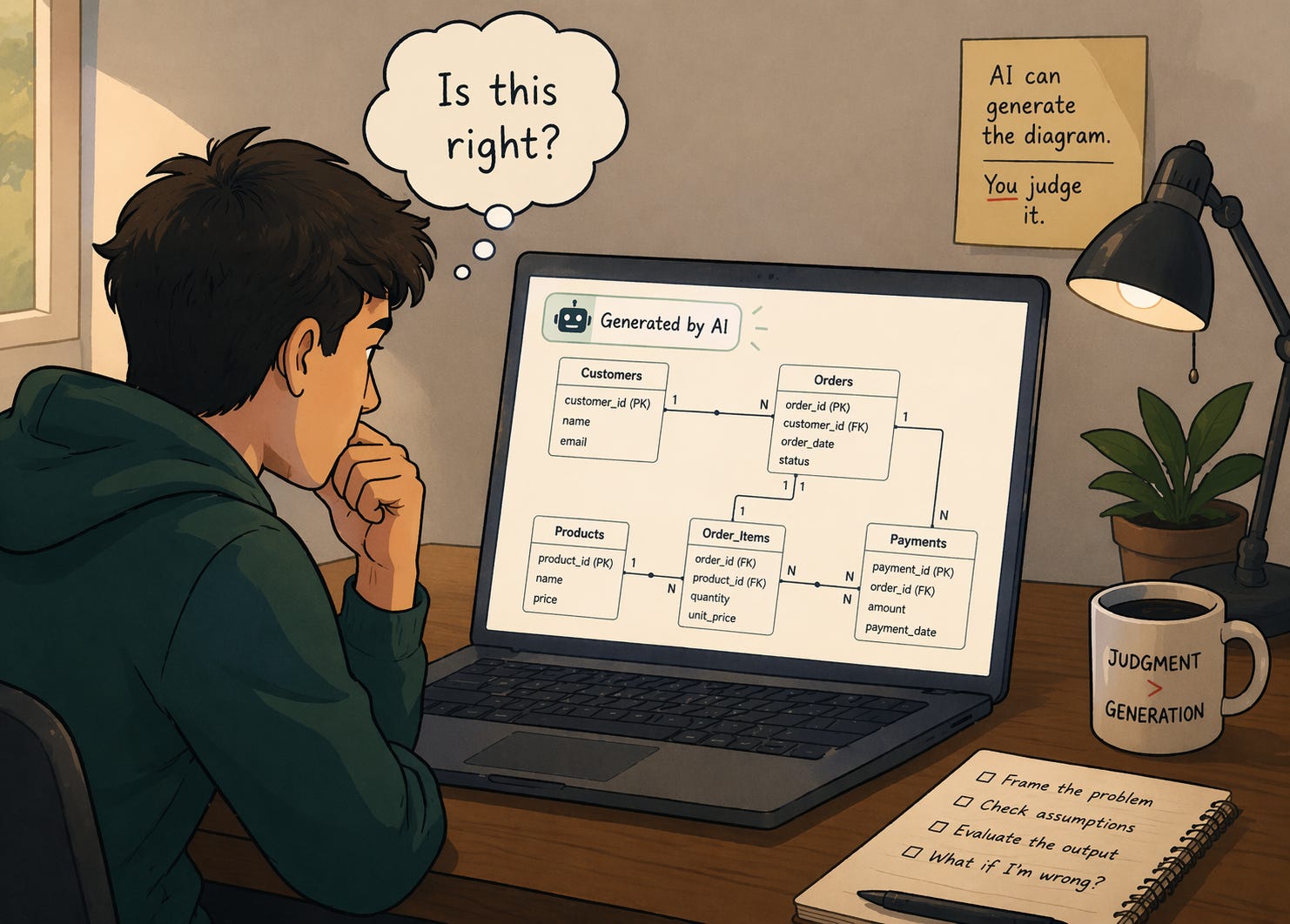
Last semester, a student stopped me in mid-lecture. We were discussing how an online retailer should organize its customer and order data when he typed a few sentences into his laptop and turned the screen toward me. ChatGPT had produced a clean data model — customers, orders, products, payments — that looked remarkably like the diagrams I normally spend weeks teaching students to construct themselves.
For a moment, my entire course felt strangely obsolete. But only for a moment. Then, I realized something even more troubling: nobody in the room — neither the student who had generated it, nor any of his classmates — could say whether the AI-generated model was correct.
I suspect many faculty have had a version of this moment. The most common response is to treat it as an assessment problem: How do we stop students from submitting AI-generated work? How do we design assignments AI can’t complete?
These are real questions. But they start in the wrong place. The deeper question is simpler and more fundamental: what do we want students to be able to do in a world of intelligent machines, and do our courses still develop those capabilities?
My answer, after redesigning a course around this question, is that generative AI has forced a reckoning not just with our assessments but with our learning outcomes. The faculty who engage that reckoning seriously will find that it leads to somewhere more interesting than a revision of academic integrity policies.
*
For decades, higher education relied on a convenient shortcut: if students could produce a certain type of artifact, we assumed they had developed the competency behind it. Writing an essay meant that a student could construct an argument. Writing code meant they understood computation. Producing an analysis meant they could reason about data. This worked because producing the artifact required mastering the competency.
But the creation of artifacts was never really the goal. It was the exercise, the mechanism by which students developed the mental models we really cared about. The essay forced students to structure an argument. The program forced them to trace the logic of an algorithm. The analysis forced them to specify a question precisely enough that a given data set could answer it. We were building cognitive capabilities. The artifact was how we made that cognitive development visible.
Generative AI has separated those two things. Students can now produce many of the artifacts without developing the capabilities that once came with them. The exercise no longer reliably produces the outcome. Which means that we need to redesign the exercise, not just the way we assess it.
*
The answer begins with distinguishing between two kinds of skills that AI has pulled apart. The first is artifact production: generating the essay, the program, the diagram, the analysis, the competency most of our learning outcomes have been built to develop, and the one generative AI has made widely accessible regardless of whether genuine understanding accompanies it.
The second is artifact reasoning: deciding what artifact should exist, directing a system toward producing it correctly, and judging whether the result answers the question it was meant to address. This is what AI cannot do. It is also what graduates are increasingly expected to do in the workplace: supervise, evaluate, and take responsibility for outputs that intelligent systems generate on their behalf.
Artifact reasoning, in turn, has two components. The first is problem framing: specifying a question precisely enough that an artifact can answer it. Consider a question deans often ask: Which courses are most effective? Before any algorithm can answer it, someone must decide what “effective” means. Higher exam scores? Greater improvement between the first and last assignment? Better performance in follow-on courses? Or something harder to measure, like the ability to apply ideas in unfamiliar situations? Each definition leads to a different data set, a different model, and ultimately a different answer. An AI system can generate dashboards and rankings once the question is posed. But unless someone frames the problem carefully, the system will produce precise answers to a vaguely defined question.
The second component of artifact reasoning is critical interpretation: reading an artifact carefully enough to know whether it answers the intended question, what assumptions it encodes, and where it might mislead. Recognizing these failures requires genuine comprehension of the underlying system, the kind that only develops through sustained engagement with the material.
Taken together, these constitute the new core capability our courses need to develop, not as an add-on to existing learning outcomes but as the organizing framework around which courses should be redesigned.
*
My database course at Boston University’s Questrom School of Business was where I worked this out. The course covers tools that are central to how organizations operate: data models, database queries, analytical dashboards. What changed was the question each course unit was designed to answer. In earlier versions: Can students produce these artifacts correctly? In the redesigned version: Can students reason about what these artifacts do?
Take data modeling, the first topic students encounter. Traditionally, students read a description of a company’s operations and drew a diagram of its key entities and relationships. The exercise ended when the diagram looked correct. Now, the class begins with a deceptively simple question: What exactly are we trying to represent?
What counts as a customer? Should payments be modeled separately from orders? What happens when a single order ships from multiple warehouses? Before drawing anything, the class must decide what aspects of a business’s messy reality should be captured as structured data, and what each choice will mean for every analysis the database will ever support. Only then do students construct models, comparing their versions with AI-generated alternatives. The interesting part comes when the diagrams differ. Each looks plausible. Each encodes different assumptions. The exercise is no longer about producing a correct diagram. It is about explaining what each diagram means.
The same shift runs through the course’s treatment of database queries. Students begin not by writing code but by clarifying the underlying business question itself. Suppose a company asks which customers generated the most revenue last month. Before writing a database query to determine the answer, the class must decide what the question really means. What counts as revenue? Does “last month” refer to orders placed or orders delivered? How should returns be handled? Only after specifying the logic do students generate the query, sometimes themselves, sometimes with AI. Their task then becomes explaining what the query actually computes. Two queries can run without errors yet answer subtly different questions. Only one answers the question that was intended.
Later in the semester, students build dashboards. But even here, the exercise begins differently: What decisions should this dashboard inform? Before creating any visualization, students must explain what questions it is meant to answer. A dashboard, they discover, is not merely a visual display. It is an argument about what the data means.
Throughout, students are encouraged to use AI tools to generate models, queries, and visualizations. But every assignment requires them to explain what the artifact does, what assumptions it relies on, and how it answers — or fails to answer — the original question. Each module begins with examples in which AI-generated outputs contain subtle errors or misleading assumptions. Once students understand that they cannot reliably evaluate AI output without gaining hands-on experience on what correct output looks like, the temptation to take shortcuts largely disappears.
By the end of the semester, class discussions had become more animated than at any point in my years teaching the course. Students are not asking how to produce the next artifact. They are asking why a design choice matters, what an analysis is hiding, and how a different framing would change the result.
*
The shift toward artifact reasoning does not mean abandoning production. Some hands-on production experience is indispensable. Students who have never written a query themselves have a genuinely difficult time evaluating queries written by AI. Without having constructed a data model from scratch, they struggle to see why two plausible-looking models might encode meaningfully different views of a business. Production is not the destination, it is the road — and there is no shortcut around it.
Students need enough production experience to be able to think with the artifacts they encounter. They don’t need to become world experts. What they need is the kind of familiarity that comes from having struggled with the construction process enough times to understand what “good” looks like, and what decisions it requires to be generated correctly.
A useful analogy: a music listener who has studied an instrument, even at an amateur level, hears differently from one who has not. They notice the difficulty of a passage. They understand what the performer chose to emphasize and what that choice cost. They can evaluate an interpretation rather than merely receive it. They do not need to perform at a professional level to reason and make judgments about what they hear. But they do need enough production experience to develop a mental model of how the music is made.
In practice, this means production exercises should remain in our courses, but we should always think of them as means to an end. The goal of having students write a query is no longer to develop query-writing fluency as an end in itself. It is to build the mental model that reasoning subsequently requires. The debrief after each production exercise matters as much as the exercise itself: not “did it work?” but “what did you have to decide to make it work, and what would have happened if you had decided differently?”
*
Every discipline that has relied on artifact production as the primary evidence of learning now faces the same reckoning.
In writing courses, the outcome that matters now is not producing a well-structured argument —AI can do that — but analyzing one: identifying where evidence is weak, explaining how conclusions depend on assumptions that might not hold, and knowing how to make improvements.
In computer science and data science, the shift is from producing correct code to identifying edge cases, understanding what a model assumes, and recognizing when an algorithm that runs is not an algorithm that works for the intended purpose.
In graphic design, the emphasis moves from generating images to judging them: articulating why a design communicates effectively, recognizing when visual choices contradict the intended message, and refining the result so that form and purpose align.
In each case, the production competency does not disappear. It becomes a prerequisite to the reasoning competency, the foundation that makes critical interpretation possible. What changes is which one we treat as the destination.
*
This is a daunting task, and professors have every incentive to evade it. It requires revisiting learning outcomes that have been stable for years and accepting that some of what we have long measured is no longer a reliable proxy for the capabilities we care about.
There is an argument, sometimes made in faculty meetings, that we should restrict AI use and preserve our existing learning outcomes. The deeper problem with this argument is that it prepares students for a world that no longer exists. The graduates we send into the workforce will spend their careers working alongside AI systems, responsible for the outputs those systems generate. A curriculum that withholds AI, or that continues treating production as the primary evidence of competency, is not protecting rigor. It is graduating students who are underprepared for what the world will ask of them.
If AI can write the code, draft the essay, and generate the analysis, what is left to learn? The answer is the hardest thing education has always tried to teach: genuine understanding, deep enough to know when the artifact in front of you is right, and what to do when it isn’t.
Funny to see this article coming out today because it is the same day that I chose to test Claude’s ability to create an iPhone app. The whole exercise took 45 minutes to get to about 99% completion.
While it made a couple of mistakes, it was quick to fix them when presented and suggest alternative ways of achieving the same goal. And in 45 minutes I had a functioning app that I could test on my phone.
Having built and led the building of apps in the past while this app was nothing major it would probably be a few days worth of work versus the sub one hour it took.
Yet, I agree that what changes here is not whether or not to bother teaching, but what we need to teach. I still had to understand enough to be able to implement the fixes, understand the development environment, and frankly in a more complex app, know what is the right architecture and understand what are the right prompts to use. We do live in interesting times!